C语言程序设计基础
Functions (函数)
计算机学院 杨已彪
yangyibiao@nju.edu.cn
提纲
-
函数的定义和调用
-
函数声明
-
实际参数
-
return语句
-
程序终止
-
递归
数组
char msg1[] = {'H', 'e', 'l', 'l', 'o', '\0'};
char msg2[] = "Hello";
char msg3[10] = {'H', 'e', 'l', 'l', 'o'};
char msg4[10] = "Hello";
char msg5[10] = {'H', 'e', 'l', 'l', 'o', '\0'};
char msg6[10] = {'H', 'e', 'l', 'l', 'o', '\0', 'W', 'O', 'R', '\0'};
char strArr[2][5] = {
{'H', 'e', 'l', 'l', 'o'},
{'n', 'j', 'u', '!', '\0'}
};
软件设计原则
复用
模块化:便于调试、代码理解
封装:隐藏实现细节,仅暴漏有限、必要的接口
函数
函数是一连串组合在一起并命名的语句.
每个函数本质上都是一个自带声明和语句的小程序.
功能优势:
-
一个程序可以分成更容易理解和修改的小块.
-
可以避免重复编写要多次使用的代码.
-
最初属于某个程序的功能可以在其他程序中重用.
函数的声明和调用
函数的声明:
int printf(const char* format, ... );
int scanf(const char* format, ... );
函数的调用:
char str[1024];
scanf("%s", str);
int a, b;
scanf("%d%d", &a, &b);
printf("a + b is : %d", a + b);
函数的声明和调用
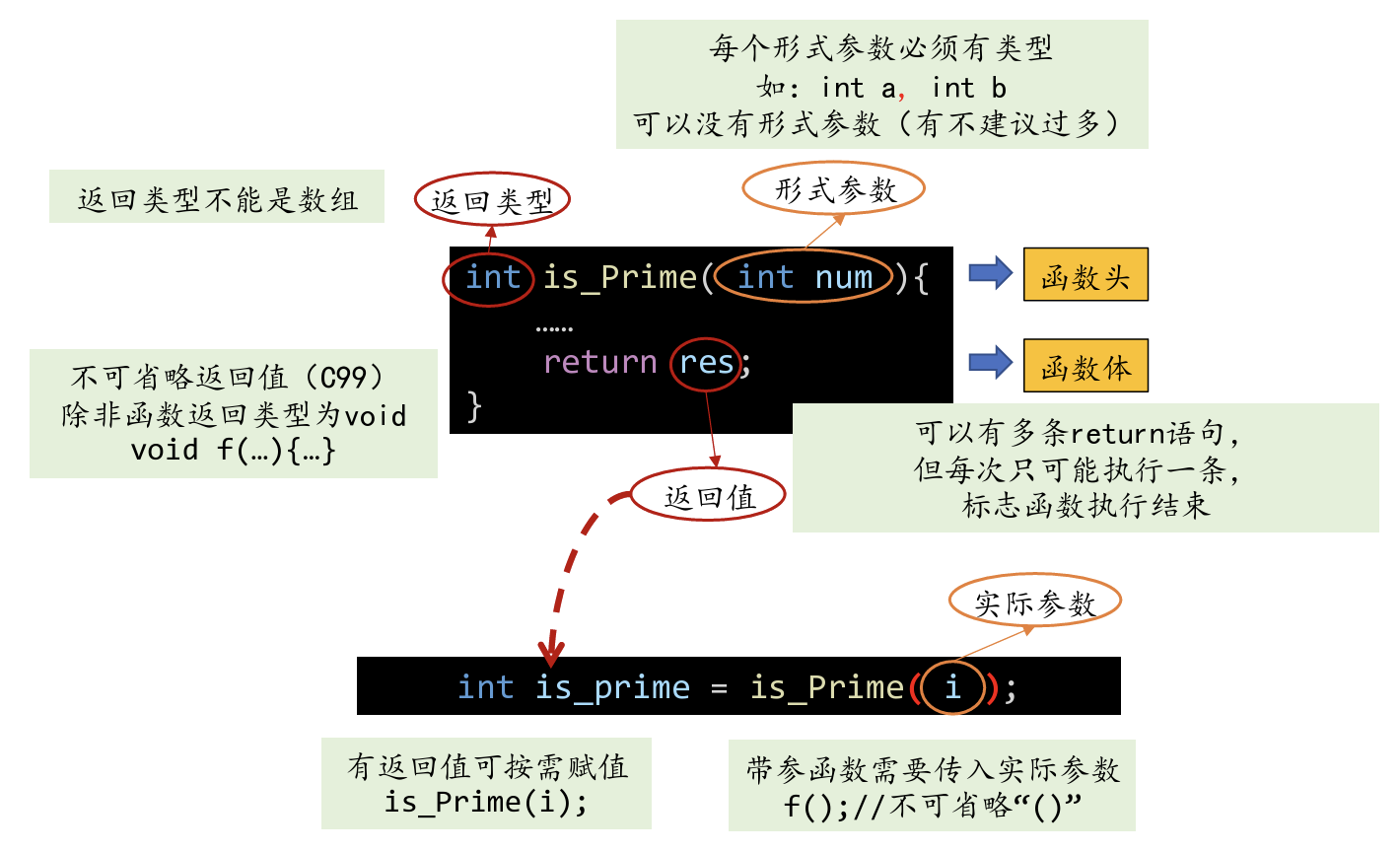
函数定义
函数定义的一般格式:
返回类型 函数名(形式参数)
{
声明
语句
}
函数定义
函数的 返回类型 是函数返回值的类型.
函数返回类型的规则:
-
函数不能返回数组.
-
指定返回类型为void表示该函数没有返回值.
-
在C89中, 如果省略返回类型, 则假定该函数的返回值是int类型.
-
在C99中, 省略返回类型是不合法的.
函数定义
函数名之后是参数列表.
需在每个形式参数前面说明其类型 , 形式参数间用逗号分隔.
如果函数没有形式参数, 则应在括号里加上单词void.
函数声明
C不要求函数的定义在其调用之前.
假设我们重新编排average.c程序, 将average函数的定义放在main函数的定义之后.
函数声明
在main中遇到average函数调用时, 编译器没有该函数的信息.
编译器不会产生错误消息, 而是假设average返回一个int值.
我们说编译器为该函数创建了一个 隐式声明.
leap.c
#include <stdio.h>
int main(void) {
int year = 0;
scanf("%d", &year);
int leap = 0; // boolean; indicator; flag
if ((year % 4 == 0 && year % 100 != 0) || (year % 400 == 0)) {
leap = 1; // printf("%d is a leap year\n", year);
}
if (leap == 0) {
printf("%d is a common year\n", year);
} else {
printf("%d is a leap year\n", year);
}
return 0;
}
leap.c
#include <stdio.h>
int is_leap_year(int);
int main(void) {
int year = 0;
scanf("%d", &year);
int leap = is_leap_year(year);
if (leap == 0) {
printf("%d is a common year\n", year);
} else {
printf("%d is a leap year\n", year);
}
return 0;
}
int is_leap_year(int n) {
if ((n % 4 == 0 && n % 100 != 0) || (n % 400 == 0)) {
return 1;
}
return 0;
}
primes.c
#include <stdio.h>
int main() {
int max;
scanf("%d", &max);
int count = 0;
for (int i = 2; i <= max; i++) {
// determine if i is a prime
int prime = 1;
for (int j = 2; j * j <= i; j++) {
if (i % j == 0) {
prime = 0;
break;
}
}
if (prime == 1) {
count++;
// printf("%d ", i);
}
}
printf("\ntotal count: %d", count);
return 0;
}
primes.c
#include <stdio.h>
int is_prime(int n) {
int prime = 1;
for (int j = 2; j * j <= n; j++) {
if (i % j == 0) {
prime = 0;
break;
}
}
return prime;
}
int main() {
int max;
scanf("%d", &max);
int count = 0;
for (int i = 2; i <= max; i++) {
// determine if i is a prime
int prime = is_prime(i);
if (prime == 1) {
count++;
}
}
printf("\ntotal count: %d", count);
return 0;
}
stars.c
#include <stdio.h>
int main() {
int lines = 0;
scanf("%d", &lines);
for (int i = 0; i < lines; i++) {
// NUm ' '
for (int j = 0; j < lines - 1 - i; j++) {
printf(" ");
}
// 2 * i + 1 '*'
for (int j = 0; j < 2 * i + 1; j++) {
printf("*");
}
if (i != lines - 1) {
printf("\n");
}
}
return 0;
}
stars-re.c
#include <stdio.h>
void print_line(int i, int lines) {
for (int j = 0; j < lines - 1 - i; j++) {
printf(" ");
}
// 2 * i + 1 '*'
for (int j = 0; j < 2 * i + 1; j++) {
printf("*");
}
if (i != lines - 1) {
printf("\n");
}
}
int main() {
int lines = 0;
scanf("%d", &lines);
for (int i = 0; i < lines; i++) {
// NUm ' '
print_line(i, lines);
}
return 0;
}
binary-search.c
#include <stdio.h>
#define LEN 10
int dictionary[LEN] = {1, 1, 5, 5, 5, 5, 5, 5, 9, 10};
int main() {
int key = 0;
scanf("%d", &key);
int index = -1;
for (int low = 0, high = LEN - 1; low <= high; ) {
int mid = (low + high) / 2;
if (key == dictionary[mid]) {
index = mid;
high = mid - 1;
} else if (key > dictionary[mid]) {
low = mid + 1;
} else {
high = mid - 1;
}
}
if (index == -1) {
printf("%d is not found\n", key);
} else {
printf("The index of %d is %d\n", index, key);
}
return 0;
}
binary-search-re.c
#include <stdio.h>
#define LEN 10
int bsearch(int dict[], int len, int key);
int main() {
int dictionary[LEN] = {1, 1, 5, 5,
5, 5, 5, 5, 9, 10};
int key = 0;
scanf("%d", &key);
int index = bsearch(dictionary, LEN, key);
if (index == -1) {
printf("%d is not found\n", key);
} else {
printf("The index of %d is %d\n", index, key);
}
return 0;
}
int bsearch(int dict[], int len, int key) {
int index = -1;
for (int low = 0, high = len - 1; low <= high;) {
int mid = (low + high) / 2;
if (key == dict[mid]) {
index = mid;
high = mid - 1;
} else if (key > dict[mid]) {
low = mid + 1;
} else {
high = mid - 1;
}
}
return index;
}
palindrome.c
selection-sort.c
selection-sort.c
selection-sort-re.c
merge.c
game-of-life.c
程序: 判定素数
prime.c程序测试一个数字是否为素数:
Enter a number: 34
Not prime
该程序定义一个名为is_prime的函数, 如果其参数是质数则返回true, 否则返回false.
is_prime将其参数n除以从2到n的平方根之间的每个数字, 只要有一个余数为0, n就不是素数.
程序: 判定素数
prime.c
/* 判断一个数是否为素数 */
#include <stdbool.h> /* C99 only */
#include <stdio.h>
bool is_prime(int n)
{
int divisor;
if (n <= 1)
return false;
for (divisor = 2; divisor * divisor <= n; divisor++)
if (n % divisor == 0)
return false;
return true;
}
int main(void)
{
int n;
printf("Enter a number: ");
scanf("%d", &n);
if (is_prime(n))
printf("Prime\n");
else
printf("Not prime\n");
return 0;
}
函数声明
#include <stdio.h>
int main(void)
{
double x, y, z;
printf("Enter three numbers: ");
scanf("%lf%lf%lf", &x, &y, &z);
printf("Average of %g and %g: %g\n", x, y, average(x, y));
printf("Average of %g and %g: %g\n", y, z, average(y, z));
printf("Average of %g and %g: %g\n", x, z, average(x, z));
return 0;
}
double average(double a, double b)
{
return (a + b) / 2;
}
函数声明
编译器无法检查传递给average的实参个数和实参类型.
它只能进行默认的实际参数提升并希望获得最好的结果.
当编译器在程序后面遇到average的定义时, 它会发现函数的返回类型实际上是double而不是int, 因此我们会得到一条出错消息.
函数声明
避免定义前调用的一种方法是每个函数的定义都出现在调用前.
可惜, 有时候无法进行这样的安排.
即使可以, 程序也会因为函数定义的顺序不自然而难以阅读.
函数声明
幸运的是, C提供了更好的解决方案: 在调用函数之前声明它.
函数声明为编译器提供函数的简要介绍, 完整定义将在以后给出.
函数声明的一般形式:
返回类型 函数名(参数);
函数的声明必须与函数的定义一致.
这是为average函数添加了声明的average.c程序.
函数声明
#include <stdio.h>
double average(double a, double b); /* DECLARATION */
int main(void)
{
double x, y, z;
printf("Enter three numbers: ");
scanf("%lf%lf%lf", &x, &y, &z);
printf("Average of %g and %g: %g\n", x, y, average(x, y));
printf("Average of %g and %g: %g\n", y, z, average(y, z));
printf("Average of %g and %g: %g\n", x, z, average(x, z));
return 0;
}
double average(double a, double b) /* DEFINITION */
{
return (a + b) / 2;
}
函数声明
函数声明也被称为函数原型.
函数原型不必指定函数形参的名字, 只要显示它们的类型即可:
double average(double, double);
但最好不要省略形参的名字.
函数声明
在调用函数之前, 须先对其进行声明或定义.
调用函数时, 如果此前编译器未见其声明或定义, 会导致出错.
实际参数
在C中, 参数是通过值传递的:
-
调用函数时, 计算出每个实际参数的值, 并将其赋值给相应的形式参数.
-
函数执行时, 对形式参数的改变不会影响实际参数的值, 形式参数包含的是实际参数值的副本.
实际参数
参数按值传递既有优点也有缺点.
因为形式参数的修改不会影响到对应的实际参数, 可以把形式参数作为函数内的变量来使用, 从而减少需要的变量的数量.
实际参数
以下函数, 计算数字x的n次幂: xn
int power(int x, int n)
{
int i, result = 1;
for (i = 1; i <= n; i++)
result = result * x;
return result;
}
实际参数
n是原始指数的副本, 函数可以安全修改它, 从而不再需要变量i:
int power(int x, int n)
{
int result = 1;
while (n-- > 0)
result = result * x;
return result;
}
实际参数
C对参数按值传递的要求使得编写某些类型的函数变得困难.
假设需要一个将double型的值分解为整数和小数部分的函数.
函数不能返回两个数, 尝试将两个变量传递给函数并修改它们:
void decompose(double x, long int_part, double frac_part)
{
int_part = (long) x;
frac_part = x - int_part;
}
实际参数
函数调用:
decompose(3.14159, i, d);
可惜的是, i和d不会因为赋值给int_part和frac_part而受到影响.
第 11 章展示了如何使decompose函数奏效.
实际参数的转换
C允许实际参数的类型与形式参数的类型不匹配的函数调用.
实际参数如何转换取决于编译器在调用函数之前是否已经遇到函数的原型(或函数的完整定义).
实际参数的转换
编译器在调用之前遇到了原型.
每个参数的值都隐式转换为相应形式参数的类型, 类似赋值一样.
示例: 如果将int型的实际参数传递给期望得到double型参数的函数, 则该实际参数将自动转换为double类型.
实际参数的转换
编译器在调用之前没有遇到原型.
编译器执行默认的实际参数提升:
float类型的实际参数转换为double类型.
执行整值提升, 把char和short类型的实际参数转换为int类型. (C99为整数提升)
实际参数的转换
依赖默认的实际参数提升是危险的, 例如:
#include <stdio.h>
int main(void)
{
double x = 3.0;
printf("Square: %d\n", square(x));
return 0;
}
int square(int n)
{
return n * n;
}
在调用square时, 编译器不知道它需要一个int类型的参数.
实际参数的转换
编译器在x上执行默认的实际参数提升, 但没有任何效果.
函数期望int类型的实际参数, 却获得了double类型值, 所以调用square将产生无效的结果.
将square的实际参数强制转换为正确的类型可以解决该问题:
printf("Square: %d\n", square((int) x));
更好的解决方案是在调用square之前提供该函数的原型.
C99中, 没有提供函数声明或定义时调用square函数是错误的.
数组型实际参数
当函数参数是一维数组时, 可以不指定数组的长度:
int f(int a[]) /* 没有指定长度 */
{
…
}
C没有为函数提供任何简单的方法来确定传递给它的数组的长度.
我们必须提供长度(如果函数需要它)作为额外的参数.
数组型实际参数
例子:
int sum_array(int a[], int n)
{
int i, sum = 0;
for (i = 0; i < n; i++)
sum += a[i];
return sum;
}
由于需要知道数组a的长度, 必须将它作为第二个参数提供.
数组型实际参数
sum_array的原型具有以下形式:
int sum_array(int a[], int n);
通常情况下, 如果愿意, 可以省略参数名称:
int sum_array(int [], int);
数组型实际参数
调用sum_array时, 第一个参数是数组的名字, 第二个是它的长度:
#define LEN 100
int main(void)
{
int b[LEN], total;
…
total = sum_array(b, LEN);
…
}
注: 在将数组名称传递给函数时, 不要在数组名称后放置方括号:
total = sum_array(b[], LEN); /*** WRONG ***/
数组型实际参数
函数无法检查传入的数组长度的正确性.
我们可以利用这一点来告诉函数, 数组的长度比实际情况小.
假设b数组有100个元素, 但是实际仅存储了50个数.
对前50个元素进行求和:
total = sum_array(b, 50);
数组型实际参数
注意不要告诉函数, 数组型实际参数比实际情况大:
total = sum_array(b, 150); /*** WRONG ***/
sum_array函数将超出数组的末尾, 导致未定义的行为.
数组型实际参数
函数可以更改数组形式参数的元素, 更改会反映在实际参数中.
通过在每个数组元素中存储0来修改数组的函数:
void store_zeros(int a[], int n)
{
int i;
for (i = 0; i < n; i++)
a[i] = 0;
}
调用store_zeros:
store_zeros(b, 100);
修改数组型实际参数元素的能力似乎与C按值传递参数相矛盾?
数组型实际参数
如果形式参数是多维数组, 声明参数时只能省略第一维的长度.
修改sum_array使得a是一个二维数组, 必须指定a中的列数:
#define LEN 10
int sum_two_dimensional_array(int a[][LEN], int n)
{
int i, j, sum = 0;
for (i = 0; i < n; i++)
for (j = 0; j < LEN; j++)
sum += a[i][j];
return sum;
}
数组型实际参数
无法传递具有任意列数的多维数组是很讨厌的.
通常可以通过使用指针数组来解决这个问题.
C99的变长数组形式参数提供了一个更好的解决方案.
变长数组形式参数 (C99)
C99 允许使用可变长度数组作为参数.
考虑sum_array函数:
int sum_array(int a[], int n)
{
…
}
这样的定义使得n和数组a的长度之间没有直接联系.
尽管函数体将n视为a的长度, 但数组实际长度可能大于或小于n.
变长数组形式参数 (C99)
如果使用变长数组形式参数, 我们可以明确声明数组a的长度为n:
int sum_array(int n, int a[n])
{
…
}
第一个参数(n)的值指定第二个参数(a)的长度.
:fa-lightbulb-o: 这里交换了参数顺序, 使用变长数组形式参数时, 顺序很重要.
变长数组形式参数 (C99)
新版本的sum_array函数的原型有好几种写法.
一种写法是让它看起来与函数定义一样:
int sum_array(int n, int a[n]); /* Version 1 */
另一种写法是用是*取代数组长度:
int sum_array(int n, int a[*]); /* Version 2a */
变长数组形式参数 (C99)
使用*符号的原因是参数名称在函数声明中是可选的.
如果省略第一个参数的名称, 就无法指定数组的长度为n, 但*提供了一个线索, 数组的长度与形参列表中较早出现的参数有关:
int sum_array(int, int [*]); /* Version 2b */
变长数组形式参数 (C99)
将方括号留空也合法, 就像我们通常在声明数组参数时那样:
int sum_array(int n, int a[]); /* Version 3a */
int sum_array(int, int []); /* Version 3b */
但是将括号留空不是一个好的选择, 因为它没有说明n和a之间的关系.
变长数组形式参数 (C99)
一般来说, 变长数组形式参数的长度可以是任意表达式.
连接两个数组a和b, 将结果存储到数组c中的函数:
int concatenate(int m, int n, int a[m], int b[n], int c[m+n])
{
…
}
指定c长度的表达式涉及另两个参数, 但通常它可以使用函数外部的变量, 甚至可以调用其他函数.
变长数组形式参数 (C99)
一维变长数组形式参数的用处有限.
它们通过说明数组参数的长度来使函数声明或定义更具描述性.
不会执行额外的错误检查, 数组参数仍然可能太长或太短.
—`
return语句
非void的函数必须使用return语句来指定它将返回的值.
return语句的 格式:
return 表达式;
表达式通常只是常量或变量, 但也可以是更复杂的表达式:
return 0;
return status;
return n >= 0 ? n : 0;
return语句
如果return语句中表达式的类型与函数的返回类型不匹配, 则表达式将被隐式转换为返回类型.
如果声明函数返回int型值, 但return语句包含double类型表达式, 则表达式的值将被转换为int类型.
程序终止
通常, main的返回类型是int:
int main(void)
{
…
}
以往的C常省略main的返回类型, 利用的是返回类型默认int的传统:
main()
{
…
}
程序终止
省略函数的返回类型在C99中是不合法的, 因此最好不要这么做.
在main的参数列表中省略void是合法的, 但最好包含它.
程序终止
main返回的值是一个状态码, 在程序终止时可以检测 状态码.
如果程序正常终止, main应该返回0.
为了指示异常终止, main应该返回一个非0的值.
确保每个C程序都返回一个状态码是一种很好的做法.
exit函数
main中执行return语句是终止程序的一种方法.
另一个是调用exit函数, 它属于<stdlib.h>头.
传递给exit的实际参数与main的返回值具有相同的含义: 两者都表示程序在终止时的状态.
为了表示正常终止, 传递0:
exit(0); /* normal termination */
exit函数
由于0有点模糊, 所以C允许用EXIT_SUCCESS来代替(效果一样):
exit(EXIT_SUCCESS);
传递EXIT_FAILURE表示异常终止:
exit(EXIT_FAILURE);
-
EXIT_SUCCESS和EXIT_FAILURE是定义在<stdlib.h>中的宏. -
EXIT_SUCCESS和EXIT_FAILURE的值是由实现定义的, 通常为0和1.
exit函数
main中的语句
return 表达式;
等价于
exit(表达式);
return和exit的区别在于:
-
无论哪个函数调用exit都会导致程序终止.
-
return语句仅当由main函数调用时才会导致程序终止.
递归
如果函数调用自身, 则它是递归的.
以下函数利用公式n!=n×(n–1)!递归地计算n!:
int fact(int n)
{
if (n <= 1)
return 1;
else
return n * fact(n - 1);
}
递归
要了解递归是如何工作的, 让我们来跟踪语句的执行
i = fact(3);
- fact(3) 发现 3≤1 不成立, 所以调用
- fact(2), 发现 2≤1 不成立, 所以调用
- fact(1), 发现 1≤1 成立, 所以返回1, 导致
- fact(2) 返回 2×1=2, 导致
- fact(3) 返回 3×2=6.
递归
以下递归函数使用公式xn=x×xn–1计算xn.
int power(int x, int n)
{
if (n == 0)
return 1;
else
return x * power(x, n - 1);
}
递归
把条件表达式放入return语句中可以精简power函数:
int power(int x, int n)
{
return n == 0 ? 1 : x * power(x, n - 1);
}
fact和power都会在调用时小心地测试终止条件.
所有递归函数都需有终止条件以防止无限递归.
快速排序算法
递归用于函数调用自身两次或多次的复杂算法.
递归经常作为分治法的结果自然地出现.
分治法把大问题分成多个小问题, 采用相同算法分别解决小问题.
快速排序算法
快速排序算法是分治法的经典例子.
假设要排序的数组下标从1到n.
快速排序算法
- 选择一个数组元素e (“分割元素”), 然后重新排列数组, 使元素1,…,i–1都小于或等于e, 元素i包含e, 而元素i+1,…,n都大于或等于e .
- 通过递归地采用快速排序方法对元素1,…,i–1进行排序.
- 通过递归地采用快速排序方法对元素i+1,…,n进行排序.
快速排序算法
快速排序算法的第1步很关键.
有多种方法可以分割数组.
下面使用一种易于理解但不是特别高效的方法.
该算法依赖于两个名为low和high的"标记", 跟踪数组中的位置.
快速排序算法
- 最初, low指向第一个元素, high指向末尾元素.
- 首先将第一个元素(分割元素)复制到一个临时位置, 在数组中留下一个"空位".
- 接下来, 从右到左移动high, 直到它指向一个小于分割元素的元素.
- 然后把这个元素复制给low指向的空位, 这会产生一个新空位(由high指向).
- 现在从左到右移动low, 寻找比分割元素大的元素. 当找到时, 将它复制到high指向的空位.
- 重复该过程, 直到low和high在一个空位处相遇.
- 最后, 将分割元素复制给空位.
快速排序算法
对数组进行快速排序的示例:
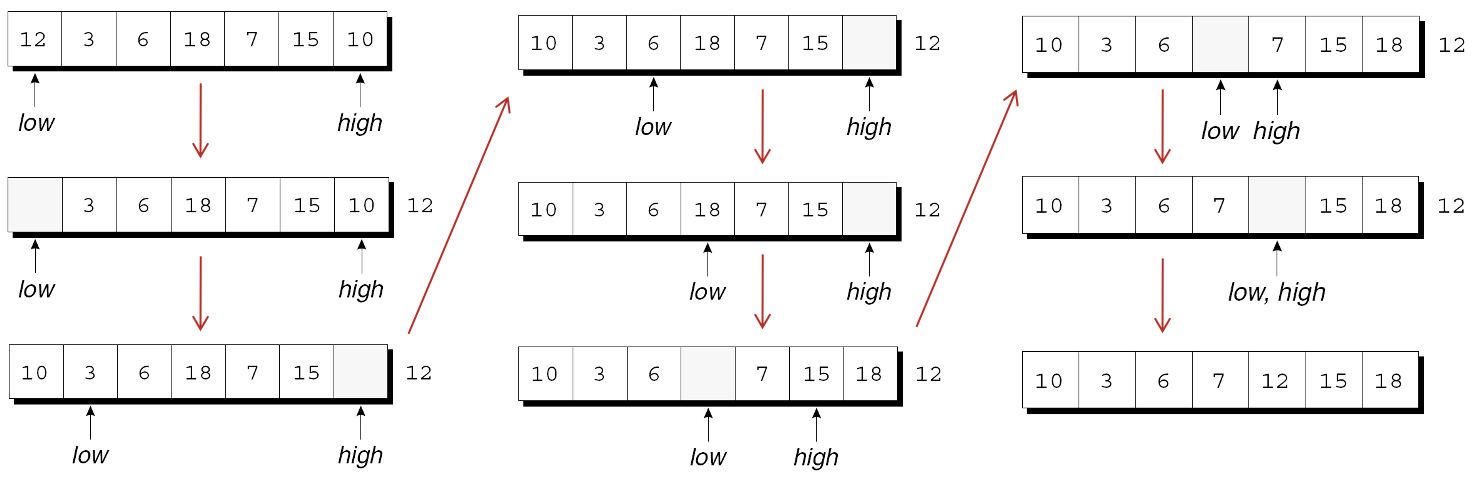
快速排序算法
由最终图可知, 分割元素左边的所有元素都小于等于12, 右边的所有元素都大于等于12.
既然数组已经被分割, 那么可以使用快速排序法递归地对数组的前4个元素(10、3、6和7)和后2个元素(15和18)进行排序.
程序: 快速排序
quicksort递归函数使用快速排序算法对整数数组进行排序.
qsort.c程序将10个数字读入一个数组, 调用quicksort对数组进行排序, 然后打印数组中的元素:
Enter 10 numbers to be sorted: 9 16 47 82 4 66 12 3 25 51
In sorted order: 3 4 9 12 16 25 47 51 66 82
对数组进行分割的代码位于一个名为split的独立函数中.
程序: 快速排序
/* 使用快速排序算法对整数数组进行排序 */
#include <stdio.h>
#define N 10
void quicksort(int a[], int low, int high);
int split(int a[], int low, int high);
int main(void)
{
int a[N], i;
printf("Enter %d numbers to be sorted: ", N);
for (i = 0; i < N; i++)
scanf("%d", &a[i]);
quicksort(a, 0, N - 1);
printf("In sorted order: ");
for (i = 0; i < N; i++)
printf("%d ", a[i]);
printf("\n");
return 0;
}
void quicksort(int a[], int low, int high)
{
int middle;
if (low >= high) return;
middle = split(a, low, high);
quicksort(a, low, middle - 1);
quicksort(a, middle + 1, high);
}
int split(int a[], int low, int high)
{
int part_element = a[low];
for (;;) {
while (low < high && part_element <= a[high])
high--;
if (low >= high) break;
a[low++] = a[high];
while (low < high && a[low] <= part_element)
low++;
if (low >= high) break;
a[high--] = a[low];
}
a[high] = part_element;
return high;
}
程序: 快速排序
提高程序性能的方法:
-
改进分割算法.
-
采用不同的方法对小数组进行排序.
-
使用非递归的快速排序.