C语言程序设计基础
数据类型
计算机学院 杨已彪
yangyibiao@nju.edu.cn
回顾
函数
函数声明/定义
数组如何作为参数传递
按值传递
数据类型
变量的数据类型决定:
-
变量取值范围
-
可采取的操作
数据类型
-
int
-
double
-
char
-
数组
数据储存
- 现代计算机中, 内存被划分为字节, 每个字节能够存储8位信息:

- 每个字节都有一个唯一的地址:

32位机: 寻址空间0∼232−1, 约4G
基本类型
C的基本(内置)类型:
-
整形
char, short, int, long, long long, bool, … -
浮点类型
float, double, long double
整数类型
C支持两种完全不同的数值类型: 整数类型和浮点类型
-
整数类型的值是整数
-
浮点类型的值可以有小数部分
整数类型又分为两类: 有符号型和无符号型
整数类型
整数
- char:一个字节(8bit)
- short:两个字节
- int:通常表示为一个字长(通常4个字节)
- long:通常表示为一个字长
- long long:8字节
一个字节(8bit)可以表达的数
- 28个
- 18 -> 00010010
整数类型
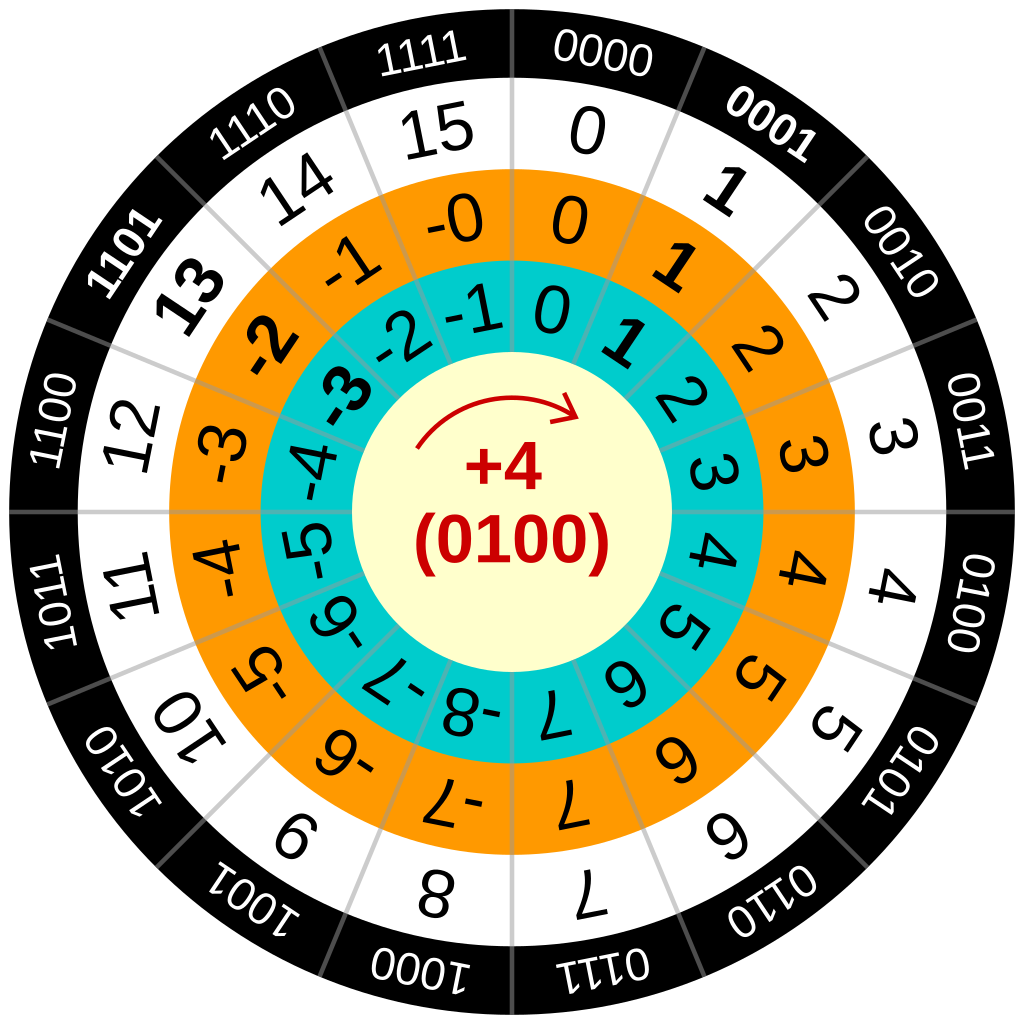
数据在内存中以二进制形式存放, E.g., signed/unsigned int
原码表示法:
| Decimal | Binary | Decimal | Binary |
|---|---|---|---|
| 0 | 0000 | -0 | 1000 |
| 1 | 0001 | -1 | 1001 |
| 2 | 0010 | -2 | 1010 |
| 3 | 0011 | -3 | 1011 |
| 4 | 0100 | -4 | 1100 |
| 5 | 0101 | -5 | 1101 |
| 6 | 0110 | -6 | 1110 |
| 7 | 0111 | -7 | 1111 |
整数的原码表示法
最高位为符号位, 易理解, 但:
- 0的表示不唯一, 不利于程序员编程 (+0/−0∗x=+0/−0?)
- 加减运算方式不统一 (7+(−1)=>0111+1001?)
- 需额外对符号位进行处理, 不利于硬件设计
- 当a<b时, 实现a−b比较困难
整数的补码表示法
模运算的用处: 在一个模运算中,一个数与它模后的余数等价

时钟是一种模12系统
整数的补码表示法
假定钟表时针指向10点, 要将它拨向6点, 则有两种拨法:
- 倒拨4格:10-4 = 6
- 顺拨8格:10+8 = 18 ≡ 6 (mod 12)
模12系统中:
- 10-4 ≡ 10+8 (mod 12)
- -4 ≡ 8 (mod 12)
则,称8是-4对模12的补码(即:-4模12补码等于8) - 同样有-5 ≡ 7 (mod 12)
- -6 ≡ 6 (mod 12)
补码(modular运算):+ 和 – 的统一
整数类型(补码)
8位二进制数模运算系统(mod 28)
- 0 -> 00000000
- 1 -> 00000001
- -1 -> 11111111
- 补码和原码可以加出一个溢出8位的0
- 0111 1111 - 0100 0000 = ?
一个负数的补码等于对应正数补码的各位取反、末位加1
- 10000000 -> -128
- 01111111 -> 127
32位十进制数模运算系统(mod 232)
整数类型(补码)
| 数值 | 二进制 | 数值 | 二进制 |
|---|---|---|---|
| 0 | 0000 | - | -> |
| 1 | 0001 | -1 | 1111 |
| 2 | 0010 | -2 | 1110 |
| 3 | 0011 | -3 | 1010 |
| 4 | 0100 | -4 | 1101 |
| 5 | 0101 | -5 | 1100 |
| 6 | 0110 | -6 | 1010 |
| 7 | 0111 | -7 | 1001 |
| - | -> | -8 | 1000 |
unsigned/signed int类型
无符号整数
- 32位整数:0x0~0xFF FF FF FF(32个1)
带符号位整数
- 补码表示法(普遍采用):各位取反末位加1
- 用加法来实现减法
- 00000000 -> 0
- 11111111 -> -1
- 10000000 -> -128
- 01111111 -> 127
- 比原码表示法多表示一个最小的负数
有符号整数和无符号整数
有符号整数: 如果为正数或0, 最左边位(符号位)为0; 如果为负数, 则符号位为1
-
最大的
16位整数的二进制表示形式是0111111111111111, 其值为32,767 (215–1) -
最大的
32位整数是01111111111111111111111111111111, 其值为2,147,483,647 (231–1)
无符号位的整数(最左边的位是数值的一部分)称为无符号整数
-
最大的
16位无符号整数是65,535 (216–1) -
最大的
32位无符号整数是4,294,967,295 (232–1)
有符号整数和无符号整数
默认情况下, C中整数变量都是有符号的——最左位是符号位
要告诉编译器变量没有符号位, 需要把它声明为unsigned类型
无符号整数主要用于系统编程和底层与机器相关的应用
整数类型
-
int类型通常是32位, 但在老的CPU上可能是16位 -
长整型(
long)可能比普通整型有更多位; 短整型(short)可能有更少的位 -
说明符
long和short以及signed和unsigned可以与int组合起来
只有6种组合可以产生不同的类型:
short int unsigned short int
int unsigned int
long int unsigned long int
说明符的顺序无关紧要, 单词int可以省略(long int可以缩写为long)
整数类型
6种整数类型中的每一种表示的取值范围因机器而异
C标准要求:
-
short int、int和long int都必须都覆盖一个确定的最小取值范围 -
int不得短于short int,long int不得短于int
整数类型
C99 提供了两个额外的标准整数类型: long long int, unsigned long long int
这两个long long类型都至少64位宽
long long int类型值的范围通常为 –263(–9,223,372,036,854,775,808) 到 263–1(9,223,372,036,854,775,807)
unsigned long long int类型值的范围通常为 0 到 264–1(18,446,744,073,709,551,615)
整数类型
C99中把short int, int, long int, long long int类型(以及signed char类型)称为标准有符号整型
unsigned short int, unsigned int, unsigned long int, unsigned long long int类型(以及unsigned char类型和_Bool类型)称为标准无符号整型
除了标准的整数类型以外, C99 标准还允许在具体实现时定义扩展的整数类型(包括有符号的和无符号的)
sizeof运算符
sizeof (类型名)
表达式的值是无符号整数, 表示存储属于类型名的值所需字节数
sizeof(char)的值始终为 1, 但其他类型的值可能有所不同
在 32 位机器上, sizeof(int)通常为 4
sizeof运算符
通常情况下sizeof运算符也可应用于常量、变量和表达式
如果i和j是int型变量, 则sizeof(i)和sizeof(i + j)在32位机器上均为4
-
与应用于类型时不同, sizeof应用于表达式时不需要括号
-
可以用sizeof i代替sizeof(i)
-
若考虑运算符优先级, 可能需要括号
-
sizeof i + j会被解释为(sizeof i) + j, 因为一元运算符优先级高于二元运算符
sizeof运算符
sizeof表达式的类型是 size_t (unsigned long int)
printf("Size of int: %lu\n", sizeof(int));
sizeof(静态运算符,编译时决定,不要在括号内做运算)
整数类型
数据类型通常取值范围
| 类型 | 字节 | 位数 | 最值范围 | 格式匹配符 |
|---|---|---|---|---|
| char | 1 | 8 | −27∼27−1 | %c, %d |
| signed char | 1 | 8 | −27∼27−1 | %c, %d |
| unsigned char | 1 | 8 | 0∼28−1 | %c, %d |
| signed short int | 2 | 16 | –215∼215−1 | %hd |
| unsigned short int | 2 | 16 | 0∼216−1 | %hu |
| signed int | 4 | 32 | −231∼231−1 | %d |
| unsigned int | 4 | 32 | 0∼232−1 | %u |
| signed long int | 4 | 32 | −231∼231−1 | %ld |
| unsigned long int | 4 | 32 | 0∼232−1 | %lu |
| signed long long int | 8 | 64 | –263∼263−1 | %lld |
| unsigned long long int | 8 | 64 | 0∼264−1 | %llu |
类型所占字节位数与特定编译器/平台相关
整数类型
64 位机上整数类型通常的取值范围:
| 类型 | 最小值 | 最大值 |
|---|---|---|
| short int | –32,768 | 32,767 |
| unsigned short int | 0 | 65,535 |
| int | –2,147,483,648 | 2,147,483,647 |
| unsigned int | 0 | 4,294,967,295 |
| long int | –263 | 263–1 |
| unsigned long int | 0 | 264–1 |
<limits.h>头文件定义了每种整数类型最小值和最大值的宏
有符号与无符号数
C语言标准规定:
- 若运算中同时有无符号和带符号整数,则按无符号整数运算
| 关系表达式 | 类型 | 结果 | 说明 |
|---|---|---|---|
| 0==0U | 无 | 00…0B = 00…0B | |
| −1<0 | 有 | 11…1B(-1) < 00…0B(0) | |
| −1<0U | 无 | ? | |
| 2147483647>−2147483647−1 | 有 | ||
| 2147483647U>−2147483647−1 | 无 | ||
| 2147483647>(int)2147483648U | 有 | ||
| −1>−2 | 有 | ||
| (unsigned)−1>−2 | 无 | ||
strlen函数返回值
size_t strlen(const char* str );
| 平台体系 | 实际类型 | 位宽 |
|---|---|---|
| 32-bit 系统 | unsigned int 或 unsigned long | 32 位 |
| 64-bit 系统(Linux/GCC/Clang) | unsigned long | 64 位 |
| 64-bit Windows(MSVC) | unsigned long long | 64 位 |
if (strlen(name1) - strlen(name2) < 0) {
printf("true");
} else {
printf("false");
}
计算机内部表示
在计算机内部只有二进制, 如何解释内存中的二进制
#include <stdio.h>
int main() {
int x = -1;
unsigned u = 2147483648; // 2^31
printf("x (int -1) = %u (u) = %d (d) \n", x, x);
printf("u (unsigned 2^31) = %u (u) = %d (d) \n", u, u);
return 0;
}
整数类型
数据在内存中以二进制形式存放, 大端/小端存储方式(inta = 33023)
- 小端: 低位字节存在低地址, 高位字节存在高地址
- 大端: 高位字节存在低地址, 低位字节存在高地址
例如:00000000 00000000 10000000 11111111
| 大端 | 小端 | |
|---|---|---|
| 低地址 | 00000000 | 11111111 | |
| 00000000 | 10000000 | | |
| 10000000 | 00000000 | |
| 高地址 | 11111111 | 00000000 |
类型转换
隐式类型转换
-
算术表达式或逻辑表达式的操作数类型不同时(常规算术转换)
-
赋值运算右侧表达式类型与左侧变量类型不匹配时
-
函数调用时实参与形参不匹配时
-
return表达式类型与返回值不同时
类型转换
为了让计算机执行算术运算, 通常要求操作数有相同的大小(相同的位数), 并以相同的方式存储
表达式中可以混合使用不同基本类型, C编译器可能需要生成将某些操作数转换成不同类型的指令, 使硬件能对表达式进行计算
-
如果将16位short型数和32位int型数相加, 编译器会将short型值转换为32位值
-
如果将int型数和float型数相加, 编译器会将int型值转换为float
类型转换
隐式转换: 编译器自动处理而无需程序员介入的转换(implicit)
显式转换: 程序员使用强制运算符进行的转换(explicit)
C有大量不同的算术类型, 因此执行隐式转换的规则较为复杂
类型转换
进行隐式转换的情况:
-
当算术或逻辑表达式中的操作数类型不相同时
-
当赋值运算符右侧表达式的类型与左侧变量的类型不匹配时
-
当函数调用中的实参类型与对应形参的类型不匹配时
-
当return语句中表达式的类型与函数返回的类型不匹配时
常用算术转换
常用算术转换适用于大多数二元运算符的操作数
表达式f + i, 若f的类型为float, i的类型为int, 则常用算术转换将会应用在表达式的各个操作数上
将i转换为float类型比将f转换为int类型更安全
-
当整数转换为float时, 可能发生的最坏情况是精度的轻微损失
-
相反, 将浮点数转换为int会导致数字的小数部分的损失
-
如果原始float数大于最大的整数或小于最小的整数, 得到的结果则毫无意义
常用算术转换
常用算术转换的策略: 将操作数转换为可以安全适用于两个数值的最狭小的数据类型
为了统一操作数的类型, 通常可以将相对狭小类型的操作数转换为另一个操作数的类型来实现(即所谓的提升)
最常用的是整值提升, 将字符或短整数转换为int类型(或在某些情况下转换为unsigned int)
执行常用算术转换的规则可以分为两种情况:
-
任一操作数的类型是浮点类型
-
两种操作数类型都不是浮点类型
常用算术转换
任一操作数的类型是浮点类型
-
如果一个操作数的类型为long double, 那么将另一操作数转换为long double类型
-
否则, 如果一个操作数的类型为double, 那么将另一操作数转换为double类型
-
否则, 如果一个操作数的类型为float, 那么将另一操作数转换为float类型
例如: 如果一个操作数的类型为long int, 另一个操作数的类型为double, 则long int类型的操作数会被转换为double类型
常用算术转换
若操作数类型都不是浮点类型,会先对两个操作数执行整值提升
然后按照下图对类型较狭小的操作数进行提升:
unsigned long int |
|---|
| ⇑ |
long int |
| ⇑ |
unsigned int |
| ⇑ |
int |
常用算术转换
当有符号与无符号操作数组合时, 把有符号操作数转换为无符号
-
此规则可能会导致隐蔽的编程错误
-
最好尽量避免使用无符号整数, 特别是不要将它与有符号整数混合使用
常用算术转换
常用算术转换示例:
char c;
short int s;
int i;
unsigned int u;
long int l;
unsigned long int ul;
float f;
double d;
long double ld;
i = i + c; /* c is converted to int */
i = i + s; /* s is converted to int */
u = u + i; /* i is converted to unsigned int */
l = l + u; /* u is converted to long int */
ul = ul + l; /* l is converted to unsigned long int */
f = f + ul; /* ul is converted to float */
d = d + f; /* f is converted to double */
ld = ld + d; /* d is converted to long double */
赋值过程中的转换
常用算术转换不适用于赋值运算
赋值运算右边的表达式会被转换为左边变量的类型:
char c;
int i;
float f;
double d;
i = c; /* c is converted to int */
f = i; /* i is converted to float */
d = f; /* f is converted to double */
赋值过程中的转换
把浮点数赋值给整型变量会丢掉该数的小数部分:
int i;
i = 842.97; /* i is now 842 */
i = -842.97; /* i is now -842 */
把某种类型的值赋给类型更狭小的变量时, 如果该值超出变量类型的范围, 将会得到无意义的结果:
c = 10000; /*** WRONG ***/
i = 1.0e20; /*** WRONG ***/
f = 1.0e100; /*** WRONG ***/
赋值过程中的转换
如果要将浮点常量赋值给float型变量, 最好加上f后缀:
f = 3.14159f;
如果没有后缀, 常量3.14159将是double类型, 可能会有警告消息
C99 中的隐式转换
C99的隐式转换规则略有不同
每个整数类型都有一个整数转换等级
从高到低排列:
- long long int, unsigned long long int
- long int, unsigned long int
- int, unsigned int
- short int, unsigned short int
- char, signed char, unsigned char
- _Bool
C99的整数提升可以将任何等级低于int和unsigned int的类型转换为int(只要该类型的所有值都可以用int类型表示)或unsigned int
C99 中的隐式转换
C99 执行常用算术转换的规则可以分为两种情况:
-
任一操作数的类型是浮点类型, 且都不是复数类型, 规则和以前一样
-
两种操作数类型都不是浮点类型
C99 中的隐式转换
两种操作数类型都不是浮点类型.
若两个操作数的类型相同, 过程结束
否则, 依次尝试以下规则:
-
若两个操作数都是有符号或都是无符号, 将转换等级较低的转换为等级较高的
-
若无符号操作数等级高于或等于有符号操作数等级, 将有符号转换为无符号类型
-
若有符号操作数类型可表示无符号操作数类型的所有值, 将无符号操作数转换为有符号操作数类型
-
否则, 将两个操作数都转换为与有符号操作数的类型相对应的无符号类型
C99 中的隐式转换
所有算术类型都可以转换为_Bool类型
如果原始值为0, 则转换结果为0; 否则结果为1
强制类型转换
C的隐式转换很方便, 但有时需要从更大程度上控制类型转换
出于这个原因, C 提供了强制类型转换
强制类型转换表达式格式:
(类型名)表达式
类型名指定表达式应转换成的类型
强制类型转换
使用强制类型转换表达式计算float类型值的小数部分:
float f, frac_part;
frac_part = f - (int) f;
f和(int)f的区别在于小数部分在强制类型转换时被丢弃
强制类型转换表达式可用于显示那些肯定会发生的类型转换:
i = (int) f; /* f 转换为 int */
强制类型转换
强制转换表达式可以用来强制编译器进行转换
float quotient;
int dividend, divisor;
quotient = dividend / divisor;
为了避免除法的结果丢弃小数部分, 需要转换操作数的类型:
quotient = (float) dividend / divisor;
将被除数转换为float类型会迫使编译器将除数也转换为float类型
强制类型转换
C将==(类型名)==视为一元运算符
一元运算符优先级高于二元运算符, 编译器会将表达式
(float) dividend / divisor
解释为:
((float) dividend) / divisor
其他实现相同效果的方法:
quotient = dividend / (float) divisor;
quotient = (float) dividend / (float) divisor;
强制类型转换
有时需要使用强制类型转换以避免溢出:
long i;
int j = 1000;
i = j * j; /* 可能发生溢出 */
使用强制类型转换可避免数据溢出问题:
i = (long) j * j;
注意, 语句
i = (long) (j * j); /*** WRONG ***/
是不对的, 因为溢出在强制类型转换之前已经发生了
整数类型
常量是在程序中以文本形式出现的数
C 允许用十进制(基数为10)、八进制(基数为8)和十六进制(基数为16)书写整数常量
整数类型
八进制数仅使用数字0到7
-
八进制数中的每一位表示一个
8的幂 -
八进制数 237 表示成十进制数就是
2×82+3×81+7×80=128+24+7=159
十六进制数是用数字0~9加上字母A~F(代表10~15)书写的
-
十六进制数中的每一位表示一个
16的幂 -
十六进制数 1AF 的十进制数值为
1×162+10×161+15×160=256+160+15=431
整数类型
十进制常量包含0~9 中的数字, 但不能以零开头:
15 255 32767
八进制常量只包含0~7中的数字, 并且必须以零开头:
017 0377 077777
十六进制常量包含0~9中的数字和a~f中的字母, 且总以0x开头:
0xf 0xff 0x7fff
十六进制常量中的字母可以是大写, 也可以是小写:
0xff 0xfF 0xFf 0xFF 0Xff 0XfF 0XFf 0XFF
整数类型
十进制整数常量的类型通常是int
如果常量的值太大而无法存储在int型中, 就用long int类型
如果出现long int不够用的罕见情况, 编译器会用unsigned long int作为最后的尝试
对于八进制或十六进制常量, 规则略有不同: 编译器将依次尝试int, unsigned int, long int, unsigned long int类型, 直到找到能表示该常数的类型
整数常量
强制编译器把常量作为长整型来处理, 需在后面加上字母L(或l):
15L 0377L 0x7fffL
为了指明是无符号常数, 可以在常量后面加上字母U(或u):
15U 0377U 0x7fffU
L和U可以结合使用:
0xffffffffUL
L和U的顺序和大小写无所谓
C99 中的整数常量
以LL或ll(两个字母的大小写必须匹配)结尾的整数常量是long long int型的
在LL或ll之前或之后添加字母U(或u)表示该整数常量是unsigned long long int型
C99 确定整数常量类型的规则与 C89 有些不同
对于没有后缀(U, u, L, l, LL, ll)的十进制常量, 其类型是int, long, long long int中能表示该值的最小类型
C99 中的整数常量
对于八进制或十六进制常量, 可能的类型顺序是int、unsigned int、long int、unsigned long int、long long int和unsigned long long int
常量后面的任何后缀都会改变可能类型的列表
-
以U(或u)结尾的常量类型一定是
unsigned int、unsigned long int和unsigned long long int中的一种 -
以L(或l)结尾的十进制常量类型一定是
long int或long long int
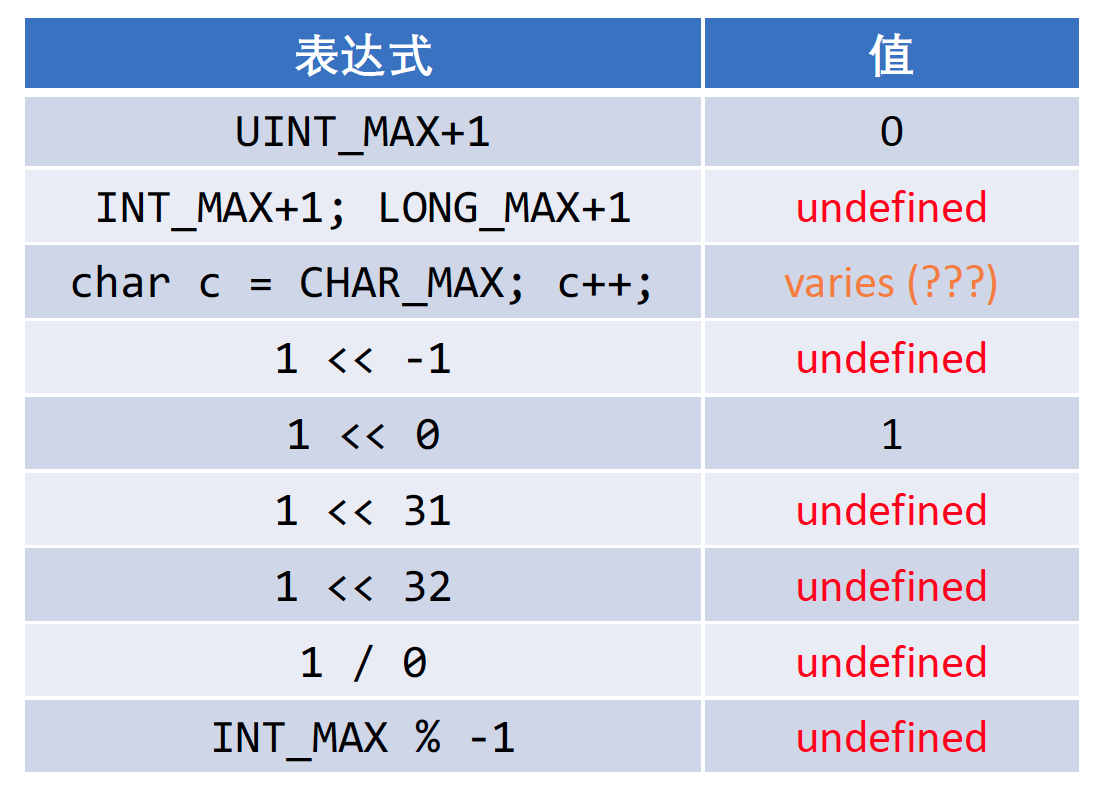
整数溢出
整数溢出是对整数执行算术运算时, 其结果因为太大而无法表示
-
对两个int值进行算术运算时, 结果必须仍然能用int类型来表示
-
否则(表示结果所需的位数太多), 就会发生溢出
整数溢出
整数溢出时的行为要根据操作数是有符号型还是无符号型来确定
有符号整数运算中发生溢出时, 行为是未定义的(不确定的)
无符号整数运算中发生溢出时, 结果是有定义的:
- 对2n取模,
n是用于存储结果的位数(如一般unsigned int是32位)
整数溢出与Undefined Behavior
Undefined behavior (UB) is the result of executing computer
code whose behavior is not prescribed by the language
specification to which the code adheres, for the current state
of the program. This happens when the translator of the source
code makes certain assumptions, but these assumptions are
not satisfied during execution. -- Wikipedia
C对UB的行为是不做任何约束的
• 常见的UB:非法内存访问(空指针解引用、数组越界、写只读内存等)、
被零除、有符号整数溢出、函数没有返回值……
• 通常的后果比较轻微,比如wrong answer, crash
整数溢出与Undefined Behavior
为了尽可能高效(zero-overhead)
- 不合法的事情的后果只好undefined 了
- Java, js, python, … 选择所有操作都进行合法性检查
为了兼容多种硬件体系结构
- 有些硬件/0 会产生处理器异常
- 有些硬件啥也不发生
- 只好undefined 了
整数溢出与Undefined Behavior
为什么整数要有多少种?
• 为了准确表达内存,做底层程序需要
• 现代计算机普遍字长32或者64位,更适合做int计算
• 现代编译器普遍会进行内存对齐,所有更短的类型实际上在内存中也可能占据一个int大小(sizeof不一致)
unsigned是否只是输出视角不同,不影响内部存储
- unsigned设计的初衷,是为了进行纯二进制运算
- 位运算:&, |, ~, ^, >>, <<,
整数溢出与Undefined Behavior
Undefined Behavior: 警惕整数溢出
读/写整数
读写无符号整数、短整数和长整数需要一些新的转换说明符
读写无符号整数时, 使用字母u、o或x代替转换说明中的d
unsigned int u;
scanf("%u", &u); /* 以10为基数读取u */
printf("%u", u); /* 以10为基数输出u */
scanf("%o", &u); /* 以8为基数读取u */
printf("%o", u); /* 以8为基数输出u */
scanf("%x", &u); /* 以16为基数读取u */
printf("%x", u); /* 以16为基数输出u */
位运算符
C 提供了六个位运算符, 它们在位级别对整数数据进行操作.
其中两个运算符执行移位操作.
其他四个执行按位求反, 按位与, 按位异或和按位或运算.
移位运算符
移位运算符将整数中的位向左或向右移动:
-
<<左移 -
>>右移
<<和>>的操作数可以是任何整数类型(包括char).
对两个操作数都会进行整数提升; 结果为提升后左操作数的类型.
移位运算符
i << j的值是将i中的位左移j位后的结果.
- 每次从i的最左端"溢出"一位, 在最右端补一个0位.
i >> j的值是将i中的位右移j位后的结果.
-
如果i是无符号类型或非负数, 则需要在左端补0.
-
如果i为负数, 则结果是由实现定义的.
移位运算符
将移位运算符应用于数字 13 的效果的示例:
unsigned short i, j;
i = 13; /* i is now 13(binary 0000000000001101) */
j = i << 2; /* j is now 52(binary 0000000000110100) */
j = i >> 2; /* j is now 3(binary 0000000000000011) */
移位运算符
要通过移位来修改变量, 需要使用复合赋值运算符<<=和>>=:
i = 13; /* i is now 13(binary 0000000000001101) */
i <<= 2; /* i is now 52(binary 0000000000110100) */
i >>= 2; /* i is now 13(binary 0000000000001101) */
移位运算符
移位运算符的优先级低于算术运算符, 这可能会引起意外:
i << 2 + 1 等同于 i <<(2 + 1), 而不是(i << 2) + 1
按位求反, 按位与, 按位异或和按位或运算符
余下的4个位运算符:
-
~按位求反 -
&按位和 -
^按位异或 -
|按位或
~运算符是一元的; 对其操作数进行整数提升.
其他运算符是二元的; 对其操作数进行常用的算术转换.
按位求反, 按位与, 按位异或和按位或运算符
~, &, ^和|运算符对其操作数中的所有位执行布尔运算.
当两个操作数的位都是 1 时, ^运算符产生 0 而|产生 1 .
按位求反, 按位与, 按位异或和按位或运算符
运算符~, &, ^和|作用的示例:
unsigned short i, j, k;
i = 21;
/* i is now 21(binary 0000000000010101) */
j = 56;
/* j is now 56(binary 0000000000111000) */
k = ~i;
/* k is now 65514(binary 1111111111101010) */
k = i & j;
/* k is now 16(binary 0000000000010000) */
k = i ^ j;
/* k is now 45(binary 0000000000101101) */
k = i | j;
/* k is now 61(binary 0000000000111101) */
按位求反, 按位与, 按位异或和按位或运算符
~运算符可以帮助使底层程序可移植性更好.
-
位全为 1 的整数:
~0 -
一个整数, 除最后五位外其他位全为 1:
~0x1f
按位求反, 按位与, 按位异或和按位或运算符
~, &, ^和|有不同的优先级:
最高 ~
&
^
最低 |
例子:
i & ~j | k; /* 等价于 */ (i &(~j)) | k;
i ^ j & ~k; /* 等价于 */ i ^(j &(~k));
使用括号有助于避免混淆.
按位求反, 按位与, 按位异或和按位或运算符
复合赋值运算符&=, ^=和|=对应于按位运算符&, ^和|:
i = 21;
/* i is now 21(binary 0000000000010101) */
j = 56;
/* j is now 56(binary 0000000000111000) */
i &= j;
/* i is now 16(binary 0000000000010000) */
i ^= j;
/* i is now 40(binary 0000000000101000) */
i |= j;
/* i is now 56(binary 0000000000111000) */
用位运算符访问位
位运算符可用于提取或修改存储在少数几个位中的数据.
常见的单位操作:
-
位的设置
-
位的清除
-
位的测试
假设:
-
i 是 16 位 unsigned short 变量.
-
最左边(或最高有效)位编号为 15 , 最低有效位编号为 0 .
用位运算符访问位
位的设置. 设置 i 的第 4 位的最简单方法是将i的值与常量0x0010进行或运算:
i = 0x0000;
/* i is now 0000000000000000 */
i |= 0x0010;
/* i is now 0000000000010000 */
如果需要设置的位的位置存储在变量 j 中, 则可以使用移位运算符来创建掩码:
i |= 1 << j; /* sets bit j */
示例: 如果 j 的值为 3, 则 1 << j 是0x0008
打印整数的二进制表达
用位运算符访问位
位的清除. 清除i的第 4 位可以使用第4位为0, 其他位为1的掩码:
i = 0x00ff;
/* i is now 0000000011111111 */
i &= ~0x0010;
/* i is now 0000000011101111 */
清除位置存储在变量中的位的语句:
i &= ~(1 << j); /* clears bit j */
用位运算符访问位
位的测试. 测试i的第 4 位是否已设置的if语句:
if(i & 0x0010) … /* tests bit 4 */
测试第j位的语句:
if(i & 1 << j) … /* tests bit j */
用位运算符访问位
如果给位命名, 使用会更容易.
假设一个数字的第0, 1和2位分别对应于蓝色, 绿色和红色.
代表三个位位置的名称:
#define BLUE 1
#define GREEN 2
#define RED 4
用位运算符访问位
设置, 清除和测试BLUE位的示例:
i |= BLUE; /* sets BLUE bit */
i &= ~BLUE; /* clears BLUE bit */
if(i & BLUE) … /* tests BLUE bit */
用位运算符访问位
同时设置, 清除或测试几个位也很容易:
i |= BLUE | GREEN;
/* sets BLUE and GREEN bits */
i &= ~(BLUE | GREEN);
/* clears BLUE and GREEN bits */
if(i &(BLUE | GREEN)) …
/* tests BLUE and GREEN bits */
if语句测试是否设置了BLUE位或GREEN位.
用位运算符访问位域
处理一组连续的位(位域)比处理单个位稍微复杂一些.
常见的位域操作:
-
修改位域
-
获取位域
用位运算符访问位域
修改位域. 修改位域需要两个操作:
-
按位与(清除位域)
-
按位或(将新的位存入位域)
例子:
i = i & ~0x0070 | 0x0050;
/* stores 101 in bits 4-6 */
&运算符清除i的第4-6位; 然后|运算符设置第4-6位.
用位运算符访问位域
为了使该示例更通用, 假设j包含要存储到i的第4-6位的值.
需要在执行按位或之前将j移位至相应的位置:
i =(i & ~0x0070) |(j << 4);
/* stores j in bits 4-6 */
|运算符的优先级低于&和<<, 因此可以删除括号:
i = i & ~0x0070 | j << 4;
用位运算符访问位域
获取位域. 获取数字右端的位域(最低有效位)很容易:
j = i & 0x0007;
/* retrieves bits 0-2 */
如果位域不在i的右端, 可以先将位域移到右端, 然后再使用&运算符提取位域:
j =(i >> 4) & 0x0007;
/* retrieves bits 4-6 */
程序: 异或加密
加密数据的最简单方法之一是使用密钥对每个字符进行异或(XOR).
假设密钥是一个&字符.
将它与字符z进行异或运算会得到\字符:
00100110 (&的ASCII码)
XOR 01111010 (z的ASCII码)
01011100 (\的ASCII码)
程序: 异或加密
通过应用相同的算法来解密消息:
00100110 (&的ASCII码)
XOR 01011100 (\的ASCII码)
01111010 (z的ASCII码)
程序: 异或加密
xor.c程序通过将每个字符与&字符进行异或来加密消息.
原始消息可以由用户输入或使用输入重定向从文件中读取.
加密的消息可以在屏幕上查看或使用输出重定向保存在文件中.
程序: 异或加密
一个名为msg的示例文件:
Trust not him with your secrets, who, when left
alone in your room, turns over your papers.
--Johann Kaspar Lavater(1741-1801)
加密msg, 并将加密后的消息保存在newmsg中的命令:
xor <msg >newmsg
newmsg的内容:
rTSUR HIR NOK QORN _IST UCETCRU, QNI, QNCH JC@R
GJIHC OH _IST TIIK, RSTHU IPCT _IST VGVCTU.
--lINGHH mGUVGT jGPGRCT(1741-1801)
程序: 异或加密
恢复原始消息并将其显示在屏幕上的命令:
xor <newmsg
程序: 异或加密
xor.c程序不会更改某些字符, 包括数字.
将这些字符与&进行异或会产生不可见的控制字符, 这在某些操作系统中会出现问题.
程序检查原始字符和新(加密)字符是否都是可打印字符.
如果不是, 程序将写原始字符而不是新字符.
xor.c
/* Performs XOR encryption */
#include <ctype.h>
#include <stdio.h>
#define KEY '&'
int main(void)
{
int orig_char, new_char;
while((orig_char = getchar()) != EOF) {
new_char = orig_char ^ KEY;
if(isprint(orig_char) && isprint(new_char))
putchar(new_char);
else
putchar(orig_char);
}
return 0;
}
读/写整数
读写短整数时, 在d、o、u或x前面加上字母h:
short s;
scanf("%hd", &s);
printf("%hd", s);
读写长整数时, 在d、o、u或x前面加上字母l:
long l;
scanf("%ld", &l);
printf("%ld", l);
读写长长整数(仅限 C99)时, 在d、o、u或x前面加上字母ll:
long long ll;
scanf("%lld", &ll);
printf("%lld", ll);
浮点类型
C 提供了3种浮点类型, 对应三种不同的浮点格式:
-
float 单精度浮点数
-
double 双精度浮点
-
long double 扩展精度浮点数
浮点类型
当精度要求不严格时, float是合适的
double为大多数程序提供了足够的精度
long double很少使用
C标准没有说明float、double和long double类型提供的精度到底是多少, 因为不同的计算机可以用不同的方法存储浮点数
大多现代计算机都遵循 IEEE 标准 754(即IEC 60559)的规范
实数非常非常多
- 只能用32/64-bit 01串来表述一小部分实数
- 确定一种映射方法,把一个01串映射到一个实数
- 运算起来不太麻烦
- 计算误差不太可怕
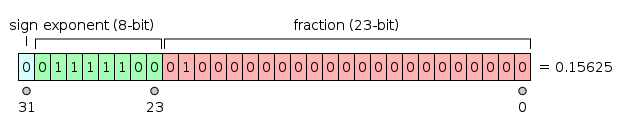
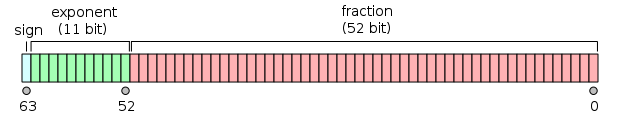
IEEE 浮点标准
IEEE标准提供了两种主要的浮点数格式: 单精度(32 位)和双精度(64 位)
数值以科学记数法的形式存储, 每一个数都由三部分组成: 符号、指数和小数
在单精度格式中, 指数长度为8位, 而小数为23位最大值约为3.40×1038, 精度是6 个十进制数字
浮点类型
根据 IEEE 标准实现时float和double的特征:
| 类型 | 最大值 | 最小值 | 精度 |
|---|---|---|---|
| float | 1.17549×10–38 | 3.40282×1038 | 6位 |
| double | 2.22507×10–308 | 1.79769×10308 | 15位 |
在不遵循 IEEE 标准的计算机上, 此表无效
事实上, 在某些机器上, float可以有和double相同的数值集合, 或者double可以有和long double相同的数值集合
浮点数表示
实数非常非常多
- 只能用32/64-bit 01串来表述一小部分实数
- 确定一种映射方法,把一个01串映射到一个实数
- 运算起来不太麻烦
- 计算误差不太可怕
浮点数表示
IEEE 754
1 bit S, 23/53 bits fraction(尾数), 8/11bits Exponent(阶码, B=127)
x=(−1)S∗(1.F)∗2E−B
浮点数表示
IEEE 754
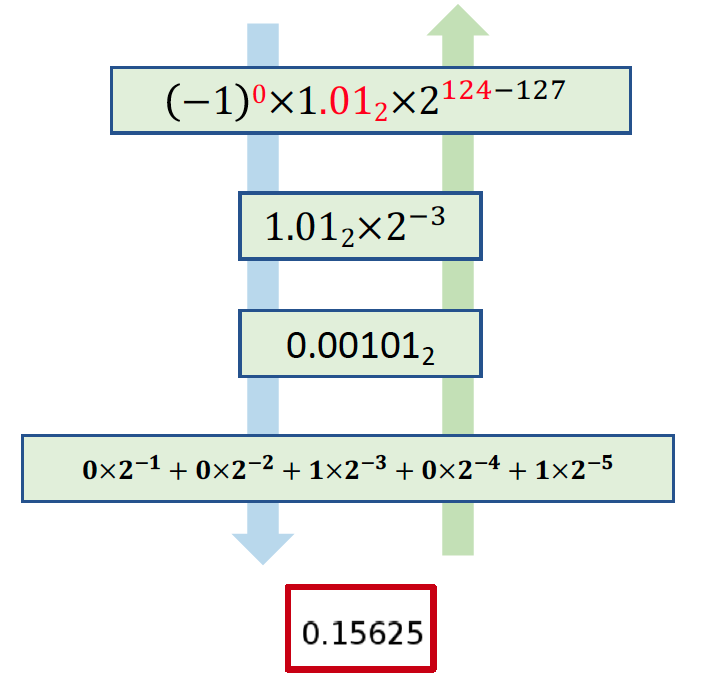

浮点数密度
一个有关浮点数大小/密度的实验 float.c
- 越大的数字,距离下一个实数的距离就越大
- 可能会带来相当的绝对误差
- 因此很多数学库都会频繁做归一化
越大的数字,距离下一个实数的距离就越大
- 可能会带来相当的绝对误差
- 因此很多数学库都会频繁做归一化
示例: - 1.000000000000000000000002×224
- 16,777,216
- 1.000000000000000000000012×224
- 16,777,218
浮点类型
比较
- a == b 需求谨慎判断(要假设自带𝜀)
- 浮点数: 𝑎 + 𝑏 + 𝑐 ≠ 𝑎 + (𝑏 + 𝑐)
浮点数的比较
// float-abrev.c 示例代码
#include <stdio.h>
int main() {
float a = 16777216.0f;
float b = a + 1.0f;
printf("a = %f\n", a);
printf("b = %f\n", b);
printf("a == b? %s\n", a == b ? "true" : "false");
return 0;
}
浮点类型
定义浮点类型特征的宏可以在<float.h>头文件中找到
在 C99 中, 浮点类型分为两类
实浮点类型(float, double, long double)
复数类型(float _Complex, double _Complex, long double _Complex)
浮点常量
浮点常量可以有多种书写方式
书写数字 57.0 的有效方式:
57.0 57. 57.0e0 57E0 5.7e1 5.7e+1 .57e2 570.e-1
浮点常量必须包含小数点或指数; 指数指明了对前面的数进行缩放所需的10 的幂次
指数必须以字母E(或e)开头可选符号+或-在E(或e)之后
浮点常量
默认情况下, 浮点常量以双精度数的形式存储
要表明只需要单精度, 可以在常量的末尾加上字母F或f, 如57.0F
要表明一个常量必须以long double格式存储, 可以在常量的末尾加上字母L或l, 如57.0L
读/写浮点数
转换说明符%e、%f和%g用于读写单精度浮点数
读取double类型的值时, 将字母l放在e、f或g前面:
double d;
scanf("%lf", &d);
我的批注 字母 l 仅用于scanf函数格式串, 不用于printf函数格式串
-
printf函数格式串中, 转换e、f和g可用于写float或double类型的值
-
读写long double类型的值时, 将字母L放在e、f或g前
字符类型
唯一还没讨论的基本类型是char类型
char类型的值可能因计算机而异, 不同的计算机可能有不同的字符集
字符集
最常用的字符集是ASCII(美国信息交换标准码)字符集, 它用7位代码表示128个字符
ASCII码中, 数字0~9用0110000~0111001码来表示, 大写字母A~Z用1000001~1011010码表示
| 数字 | 码 | 数字 | 码 |
|---|---|---|---|
| 0 | 0110000 | 5 | 0110100 |
| 1 | 0110001 | 6 | 0110101 |
| 2 | 0110010 | 7 | 0110111 |
| 3 | 0110011 | 8 | 0111000 |
| 4 | 0110100 | 9 | 0111001 |
字符集
char类型的变量可以用任何单字符赋值:
char ch;
ch = 'a'; /* 小写字母 a */
ch = 'A'; /* 大写字母 A */
ch = '0'; /* 0 */
ch = ' '; /* 空格 */
我的启示 字符常量需要用单引号括起来, 而不是双引号
字符操作
在 C 中字符的操作很简单, 因为C把字符当作小整数进行处理
在 ASCII 码中, 字符的取值范围是0000000∼1111111, 可以看成是0 127的整数
字符'a'的值是97, 'A'的值是65, '0'的值是48, ' '的值是32
字符常量实际上是int类型而不是char类型
字符操作
当计算中出现字符时, C 使用它对应的整数值
考虑以下示例, 假设采用ASCII字符集:
char ch;
int i;
i = 'a'; /* i is now 97 */
ch = 65; /* ch is now 'A' */
ch = ch + 1; /* ch is now 'B' */
ch++; /* ch is now 'C' */
字符操作
可以像数字那样对字符进行比较
将小写字母转换为大写字母的if语句:
if ('a' <= ch && ch <= 'z')
ch = ch - 'a' + 'A';
'a' <= ch 这样的比较使用的是字符所对应的整数值
这些值取决于使用的字符集, 因此使用<、<=、>和>=比较字符的程序可能不可移植
字符操作
字符具有与数字相同的属性, 这一事实会带来好处
例如, 可以让for语句中的控制变量遍历所有大写字母:
for (ch = 'A'; ch <= 'Z'; ch++) …
将字符视为数字的缺点:
-
可能导致编译器无法捕获的错误
-
允许无明确含义的表达式, 例如:
'a' * 'b' / 'c' -
可能会妨碍可移植性, 因为程序可能依赖于对字符集的假设
有符号字符和无符号字符
char类型与整数类型一样存在有符号和无符号两种
-
有符号字符的取值范围是
–128~127 -
无符号字符的取值范围是
0~255
一些编译器将char视为有符号类型, 有些则视为无符号类型
C 允许使用signed和unsigned来修饰char:
signed char sch;
unsigned char uch;
有符号字符和无符号字符
C89 使用术语整值类型来统称整数类型和字符类型
枚举类型也属于整数类型
C99 不使用术语整值类型
相反, 它将整数类型的含义扩展为包括字符类型和枚举类型
C99 的_Bool类型被认为是无符号整数类型
算术类型
整数类型和浮点类型统称为算术类型
C89中算术类型的分类:
-
整值类型
-
字符类型(
char) -
有符号整型(
signed char, short int, int, long int) -
无符号整型(
unsigned char, unsigned short int, unsigned int, unsigned long int) -
枚举类型
-
浮点类型(
float、double, long double)
算术类型
C99 分类更复杂:
-
整数类型
-
字符类型(
char) -
有符号整型, 包括标准的(
signed char, short int, int, long int, long long int)和扩展的 -
无符号整型, 包括标准的(
unsigned char, unsigned short int, unsigned int, unsigned long int, unsigned long long int, _Bool)和扩展的 -
枚举类型
-
浮点类型
-
实数浮点类型(
float, double, long double) -
复数类型(
float_Complex, double_Complex, long double_Complex)
转义序列
字符常量通常是用单引号括起来的单个字符
某些特殊字符(包括换行符)不能以这种方式书写, 不可见的(非打印字符)或者无法从键盘输入
转义序列提供了一种表示这些字符的方法
有两种转义序列: 字符转义序列和数字转义序列
转义序列
完整的字符转义序列集合:
| Name | Escape Sequence |
|---|---|
| Alert (bell) | \a |
| Backspace | \b |
| Form feed | \f |
| New line | \n |
| Carriage return | \r |
| Horizontal tab | \t |
| Vertical tab | \v |
| Backslash | \\ |
| Question mark | \? |
| Single quote | \' |
| Double quote | \" |
转义序列
字符转义很方便, 但并非所有无法打印的ASCII字符都存在转义
字符转义也无法用于表示基本128个ASCII字符之外的字符
数字转义序列可以表示任何字符, 可以解决此问题
特殊字符的数字转义序列使用字符的八进制或十六进制值
例如, 某个ASCII转义字符(十进制值为27)的八进制值为33, 十六进制值为1B
转义序列
八进制转义序列由\后跟一个最多三个数字的八进制数组成, 例如\33或\033
十六进制转义序列由\x后跟一个十六进制数组成, 例如\x1b或\x1B
x必须小写, 但十六进制数字不限大小写
转义序列
当用作字符常量时, 转义序列必须用单引号括起来
例如, 表示转义字符的常量可以写作'\33'(或'\x1b')
转义序列往往有点隐晦, 可以使用#define给它们命名:
#define ESC '\33'
转义序列也可以嵌入到字符串中
字符处理函数
C的toupper库函数是一种快速且可移植的大小写转换方法:
ch = toupper(ch);
toupper返回其参数的大写版本
调用toupper的程序需要包含头文件:
#include <ctype.h>
C 函数库提供了许多其他有用的字符处理函数
用scanf和printf读/写字符
转换说明%c允许scanf和printf读写单个字符:
char ch;
scanf("%c", &ch); /* 读取一个字符 */
printf("%c", ch); /* 写入一个字符 */
scanf不会跳过空白字符
强制scanf读取字符前跳过空白字符, 需在转换说明%c前加空格:
scanf(" %c", &ch);
用scanf和printf读/写字符
scanf读字符不会跳过空格, 可检查读取的字符是否是换行符
以下代码循环读取并忽略当前输入行中剩余的所有字符:
do {
scanf("%c", &ch);
} while (ch != '\n');
-
循环退出时, ch变量一定是换行符
-
下次调用scanf时, 它将读取下一输入行中的第一个字符
用getchar和putchar读/写字符
单字符输入和输出, getchar和putchar是scanf和printf的替代方法
putchar用于输出单个字符:
putchar(ch);
每次调用getchar时, 它都会读取一个字符并将其返回:
ch = getchar();
getchar返回一个int值而不是char值, 因此ch通常具有int类型
与scanf一样, getchar在读取时不会跳过空白字符
用getchar和putchar读/写字符
使用getchar和putchar(而不是scanf和printf)可以节省执行时间
getchar和putchar比scanf和printf逻辑简单得多
scanf和printf旨在按不同格式读写多种类型的数据
getchar和putchar通常被实现为宏以提高速度
getchar常用于多种C语言的惯用法: 搜索字符、跳过字符等
用getchar和putchar读/写字符
考虑以下scanf循环, 我们曾用它来跳过输入行剩余部分:
do {
scanf("%c", &ch);
} while (ch != '\n');
使用getchar重写可以得到以下代码:
do {
ch = getchar();
} while (ch != '\n');
用getchar和putchar读/写字符
将getchar的调用移到控制表达式中可以精简循环:
while ((ch = getchar()) != '\n')
;
不需要ch变量也可以将getchar的返回值与换行符进行比较:
while (getchar() != '\n')
;
用getchar和putchar读/写字符
getchar在跳过字符的循环以及搜索字符的循环中很有用
使用getchar语句跳过空白字符:
while ((ch = getchar()) == ' ')
;
当循环终止时, ch将包含getchar遇到的第一个非空白字符
用getchar和putchar读/写字符
我的启示 混合使用getchar和scanf时要小心
scanf函数倾向于遗留下它扫视过但未读取的字符(包括换行符):
printf("请输入一个整数: ");
scanf("%d", &i);
printf("输入命令: ");
command = getchar();
-
在读取输入至i的同时, scanf调用将会留下没有消耗掉的任意字符(不用, 放回)
-
getchar函数随后将取回第一个剩余字符(用掉, 不放回)
程序: 确定消息的长度
length.c程序显示用户输入的消息的长度:
Enter a message: Brevity is the soul of wit.
Your message was 27 character(s) long.
长度包括空格和标点符号, 但不包括消息末尾的换行符
scanf和getchar都可以读取字符, 但程序员大多会选择getchar
length2.c没有使用变量存储由getchar读取的字符
程序: 确定消息的长度
length.c
/* 确定消息的长度 */
#include <stdio.h>
int main(void)
{
char ch;
int len = 0;
printf("Enter a message: ");
ch = getchar();
while (ch != '\n') {
len++;
ch = getchar();
}
printf("Your message was %d character(s) long.\n", len);
return 0;
}
程序: 确定消息的长度
length2.c
/* 确定消息的长度 */
#include <stdio.h>
int main(void)
{
int len = 0;
printf("Enter a message: ");
while (getchar() != '\n')
len++;
printf("Your message was %d character(s) long.\n", len);
return 0;
}
类型定义
#define指令可用于创建一个宏, 定义布尔型数据:
#define BOOL int
更好的方法是利用类型定义的特性:
typedef int Bool;
现在, Bool类型可以和内置的类型名一样使用, 例如
Bool flag; /* 与 int flag相同; */
类型定义的优点
类型定义使程序更易于理解
如果cash_in和cash_out用于存储美元数量, 则将代码
float cash_in, cash_out;
改写为下面的写法更有实际意义:
typedef float Dollars;
Dollars cash_in, cash_out;
类型定义的优点
类型定义还可以使程序更易于修改
要将Dollars重新定义为double类型, 只需更改类型定义:
typedef double Dollars;
如果不使用类型定义, 就需要找到所有存储美元数量的float类型变量并更改它们的声明
类型定义和可移植性
类型定义是编写可移植程序的重要工具
将程序从一台计算机移动到另一台计算机可能引发的问题是不同计算机上的类型取值范围可能不同
如果i是int型变量, 则赋值语句
i = 100000;
在整数为32位的机器上没问题, 但在16位的机器上会出错
类型定义和可移植性
为了更大的可移植性, 考虑使用typedef定义新的整数类型名
假设编写的程序需用变量存储产品数量, 取值范围0−50,000
可以使用long类型的变量, 但更倾向于使用int类型的变量:
-
算术运算时int比long运算速度快
-
int类型变量占用的空间较少
类型定义和可移植性
可以定义自己的数量类型, 而不使用int类型来声明数量变量:
typedef int Quantity;
并使用此类型声明变量:
Quantity q;
当把程序传输到使用较短整数的机器上时, 需更改类型定义:
typedef long Quantity;
更改Quantity的定义可能会影响Quantity类型变量的使用方式
类型定义和可移植性
C语言库用typedef为因不同的实现而可能不同的类型创建类型名
这些类型的名称通常以_t结尾, 常见的例子:
typedef long int ptrdiff_t;
typedef unsigned long int size_t;
typedef int wchar_t;
C99中<stdint.h>用typedef定义占特定位数整数类型名, 如int32_t